|
Úloha
: Realizace prediktivní analýzy, PA
|
|
|
|
|
Kód úlohy
Standardní kód úlohy v MBI.
:
|
Autor návrhu úlohy
Jméno a příjmení autora úlohy
:
|
Datum poslední úpravy
Datum poslední úpravy úlohy ve tvaru rrrr.mm.dd.
:
|
Předpokládaná pravděpodobnost užití v praxi
Předpokládaná pravděpodobnost užití úlohy v praxi, hodnoty 0 - 1. Např. 0,7 - úlohu lze využít v 7 z 10 podniků. Hodnoty jsou průběžně testovány a upřesňovány na základě anket a průzkumů.
:
|
|
|
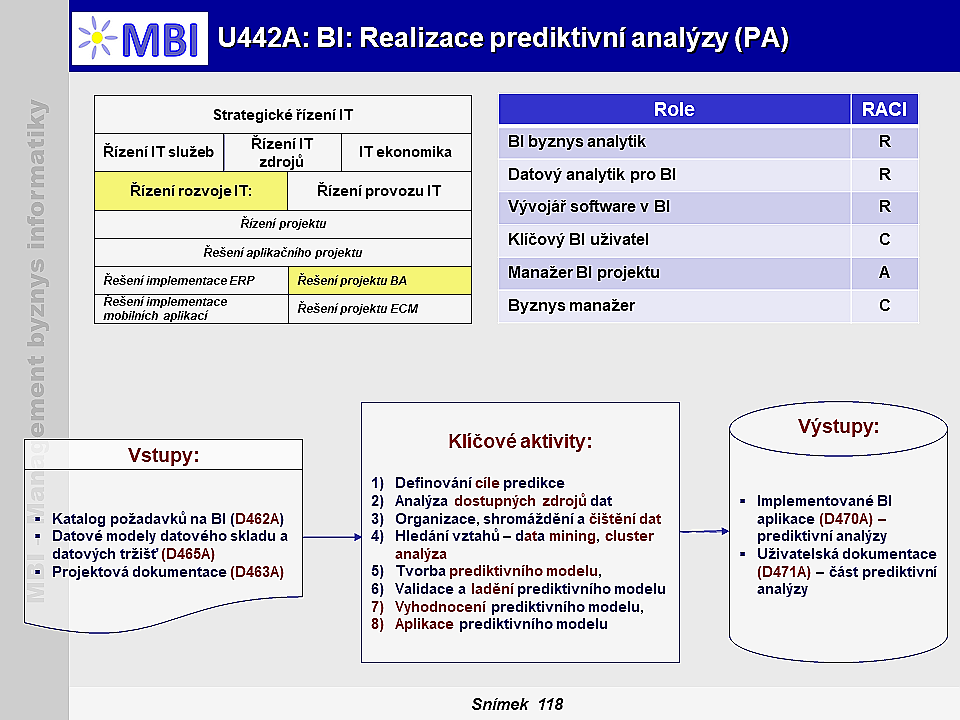
Charakteristiky úlohy
 1. Účel prediktivních analýz
- Úloha prediktivní analýzy
se realizuje až v dalších fázích řešení BI projektu
– když už je dostupný datový sklad, nebo datová tržiště s dostatečným množstvím a obsahem dat. Jejím
cílem
je:
- určit, co bude predikováno a jak se s predikcí naloží,
- shromáždit dostupná (potencionálně relevantní) data,
- vytvořit prediktivní modely z dostupných dat a využít je v byznysu.
 2. Obsah úlohy prediktivních analýz
-
Definování predikované hodnoty
(kreditní skóre klienta banky, pravděpodobnost kladné reakce na marketingovou kampaň a další.),
-
Specifikace znalosti akce nebo rozhodnutí
plynoucího z predikované hodnoty (zapůjčení peněz klientovi, zaslání letáku atd.),
-
Sběr
dostupných
relevantních dat
k predikované hodnotě,
- Nad dostupnými daty nasazení
prediktivních modelů
(rozhodovací stromy, neuronové sítě a další),
-
Výběr modelu
, který má nejlepší úspěšnost predikce,
-
Využití vybraného modelu
v provozu.
 3. Podmínky úspěšnosti úlohy
-
Velké množství dat
v dostatečném rozsahu. V ideálním případě desítky tisíc záznamů a stovky atributů, aby se projevily a potvrdily důležité obecné vztahy v datech,
-
Zájem managementu
a lidí, kterých se PA bude dotýkat,
- Vůle
upravit zaběhlé procesy
podniku na základě poznatků dosažených PA.
 4. Doporučené praktiky
- Na počátku realizace PA se provádí analýza požadavků na model. Musí být známo,
k čemu model bude sloužit
, na co bude aplikován a jak svojí predikcí pomůže. Určí se odpověď na
základní otázky
: Co má být predikováno? Jak bude s predikcí naloženo? Dobré je také vědět, kolik může úspěšná predikce vydělat nebo ušetřit. Dále se definují metriky vyhodnocení modelu a postup řešení a implementace prediktivního modelu,
- Analýza zdrojů dat ukáže,
zdali je PA nad dostupnými daty proveditelná
. Aby byla PA úspěšná, musí být data v dostatečné kvalitě a objemu.
 5. Klíčové aktivity prediktivní analýzy
-
Definování cíle predikce
- vychází z hlavních nebo z podpůrných činností podniku. Cílem je obvykle zlepšení současného stavu v dané oblasti. Samotný
cíl predikce by měl mít potenciál výrazného zlepšení, úspory, zisku
. Určí se obvykle odpověď na dvě základní otázky:
- Podle analýzy požadavků uživatelů se určuje, co je předmětem predikce, resp. co má být predikováno?
- Jak bude s predikcí naloženo, resp. jak se budou využívat a interpretovat výsledky prediktivní analýzy?
-
Analýza dostupných zdrojů dat
- identifikace všech relevantních
potencionálně využitelných zdrojů dat
. Ideální je v PA využít všechna dostupná relevantní data. Co nejvyšší úplnost relevantních dat zajistí přesnější odhady postavené na prediktivním modelu. Je tedy vhodné zahrnout jak data
z interních podnikových systémů tak z externích systémů
(např. dostupné demografické údaje, kreditní informace, informace o inflaci atp.). Analyzuje se
datová kvalita
, identifikují se slabá místa a omezení dostupných dat. Zpravidla se jako primární zdroj dat využívá
datový sklad
podniku, či
datová tržiště
vyvinuté nad datovým skladem. Především proto, že tyto datové struktury svými vlastnostmi nejlépe odpovídají potřebám prediktivní analýzy – eliminují či omezují duplicity a chyby dat, sdružují většinu/všechny podnikové systémy. Příkladem může být analýza úplnosti dat, redundance dat. Hledá se
odpověď na otázky
:
- Je vůbec prediktivní analýza na dostupných datech proveditelná?
- Jaké zdroje dat budou využity?
- Budou pro realizaci potřeba změny v samotných datových zdrojích?
- Jaké nástroje budou využity?
-
Organizace, shromáždění a čištění dat
- jedná se většinou o nejpracnější část celého procesu PA. Tato aktivita zahrnuje už
vlastní operace s daty
nad datovým zdrojem/zdroji. Hlavní činností je především
shlukování, třídění a řazení dat
k sobě podle business významu a potřeb predikce. Tato část vyžaduje výbornou technickou a business znalost dat. Je nutné,
aby data byla obsáhlá a úplná
, protože i zdánlivě nerelevantní proměnné a vztahy mezi nimi se mohou ukázat jako důležité. Skutečně nerelevantní proměnné (například s nulovými hodnotami, nebo náhodně generované hodnoty - identifikátory) se poté vyřadí ve fázi tvorby modelu. Data je nutné mít co nejúplnější a
bezchybná
, protože kvalita datového základu přímo ovlivňuje úspěšnost predikce prediktivních modelů.
Čištění dat
v sobě zahrnuje procházení záznamů a hledání chybných nebo nekompletních dat. Takové záznamy mohou mít dopad na přesnost prediktivního modelu a ideálně by měly být opraveny nebo doplněny aby byl konečný model co nejpřesnější. V této aktivitě PA se dále vytváří
odvozené vypočítané hodnoty/ukazatele
vytvořené na základě analýz, zkušeností a známých faktů z daného oboru. Tyto hodnoty mohou mít v prediktivních modelech potencionálně velice vysoké váhy, proto je potřeba věnovat jim zvýšenou pozornost a konzultovat je s ostatními pracovníky,
-
Hledání vztahů – data mining, cluster analýza -
data mining je rozbor množiny dat vybraných pro prediktivní analýzu. Je to analýza dat sloužící k
identifikování skrytých vazeb, vzorů a vztahů.
Data mining je důležitá část prediktivní analýzy, protože data a vztahy, která identifikuje jako relevantní, mohou být použity při vývoji prediktivního modelu. Data mining v procesu PA představuje
získávání znalostí o vztazích a výsledný prediktivní model je aplikací těchto znalostí
. Hlavní předností data miningu je to, že zaznamenává všechny vztahy (nebo korelace), které jsou v datech přítomny, bez ohledu a znalosti toho co je zapříčinilo.
Cluster analýza
je v PA využitá pro hledání podobností v datech. Pomocí algoritmů a metod seskupuje objekty podobných vlastností do skupin. Tato analýza může být využita k odhalení struktur v datech, ale neposkytuje interpretaci nebo vysvětlení proč tyto struktury existují,
-
Tvorba prediktivního modelu
- Prediktivní modely jsou jedním z nejdůležitějších základů prediktivní analýzy, která na nich přímo staví. Modely z dostupných dat
analyzují historická chování
k posouzení pravděpodobnosti výskytu predikovaného jevu, např. že zákazník s určitými vlastnostmi zakoupí nějaký produkt, využije nějakou službu, onemocní, pokusí se o podvod, klikne na reklamní banner na webové stránce atp. Nejdůležitější vlastností prediktivních modelů je
generalizace
. Ta zaručuje to, že model naučený z historických dat (in-sample) dokáže správně vyhodnotit data nová (out-of-sample), která do tvorby a učení modelu nevstoupila. V nejjednodušší podobě je prediktivní model v podstatě (i jediná) matematická funkce. Používají se komplexní prediktivní modely využívající principy strojového učení, které se tvoří jednoduše a rychle v nástrojích, určených pro dolování dat. Vytvořené modely se v programech sami validují, optimalizují a vyhodnocují. Existuje celá řada typů modelů, které se snaží o co nejpřesnější předpověď daného jevu a jsou vhodné na různé situace,
-
Vývoj a výběr prediktivního modelu
– modely mohou mít různou velikost a tvar v závislosti na jejich složitosti a využití, pro které jsou navrženy. Pro co nejvyšší přesnost může být použito více modelů, které jsou následně porovnávány a kombinovány. Vývoj a výběr modelu se skládá
z následujících kroků
:
- Definují se
vstupní proměnné a jejich váhy
. Váhy proměnných jsou určeny automatizovaně pomocí algoritmů a strojového učení nebo je modelář nastaví sám,
- Vybere se
co nejvhodnější model,
který co nejlépe „sedí“ na historická data (in-sample) a na nová a testovací data (out-of-sample),
- Model se
ladí a vylepšuje
, probíhá úprava proměnných, jejich vah a samotného modelu na základě testování, zpětné validace a nových dat,
-
Validace a ladění prediktivního modelu
- aby se zajistilo, že je naučený prediktivní model co nejpřesnější, musí být testován pomocí skupiny dat out-of-sample,
testovacích dat, která nijak nevstoupila do vývoje a učení modelu
. Ověřuje se schopnost predikce modelu na této skupině dat a porovnává se, jak moc se odchyluje od výsledků z učících dat. Pokud je odchylka velká, znamená to, že model není optimálně generalizován. Nabyté znalosti jsou poté aplikovány na model, který se podle nich upraví a následně opět testuje. Z důvodu vlastnosti generalizace nejsou prediktivní modely při predikci úspěšné na 100 %. V každém prediktivním modelu se objevují
2 základní typy chyb
– chybně predikovaný výskyt, ve skutečnosti není výskyt, nebo chybně predikovaný nevýskyt, ve skutečnosti výskyt. Využívané metriky modelu, pomocí kterých se vyhodnocuje úspěšnost modelu, jsou Lift, ROC, Missclassification Rate:
-
Lift
je ukazatel popisující úspěšnost a použitelnost prediktivního modelu nad bází dat. Definuje úroveň, jak moc je model úspěšnější než náhodný výběr. Úspěšnost prediktivních modelů se nad měnící se hloubkou báze dat různí. Pro usnadnění porovnání modelů nad různými hloubkami báze se zavedl pojem decil. Jeden decil obsahuje 10 % záznamů skórované báze seřazené sestupně dle predikovaného skóre. V prvním decilu obsahuje náhodný výběr 10 % všech pozitivních targetů, ve dvou decilech 20 % a v celé bázi dat jsou odhaleny všechny pozitivní targety. Nejvyššího liftu modely zpravidla dosahují na začátku v prvním decilu a má klesající tendenci. Lift náhodného výběru je 1 nad celou bází dat. Úspěšný model správně určí v prvních čtyřech decilech 80 % pozitivních targetů . Modrou barvou je zobrazen průběh křivky liftu pro tréninkovou skupinu dat, červenou pro validační. Lift modelu na obrázku X je v prvních dvou decilech přibližně 2,5. To znamená, že model (v učících datech) v prvních dvou decilech dat nalezne 50 % všech pozitivně označených hodnot target. To je o 30 % více než náhodný výběr. Od pátého decilu je úroveň predikce modelu pod úspěšností náhodného výběru. Od šestého decilu už ve zbylých datech nejsou žádné další záznamy s pozitivní hodnotou target,
-
Graf ROC (Receiver operating characteristic)
je dalším typem grafického zobrazení úspěšnosti predikce modelu . Využívá se pro vyhodnocení úspěšnosti predikce binárního targetu. Graf ROC zobrazuje na ose Y relativní četnost správně klasifikovaných pozitivních případů – senzitivitu, na ose X relativní četnost správně klasifikovaných negativních případů – specificitu. Červená křivka znázorňuje náhodný výběr a modrá prediktivní model,
-
Misclassification Rate (míra chybovosti)
je poměr špatně vyhodnocených případů k celku. Výpočet hodnoty misclassification rate = počet špatně klasifikovaných (pozitivních i negativních targetů) / celkový počet klasifikací,
-
Overfitting (také overlearning)
přeučení modelu znamená, že model špatně vyhodnocuje náhodný šum v datech, určuje důležité vztahy na základě náhodných proměnných a postrádá schopnost generalizace. Úspěšnost predikce modelu na nových datech je oproti ideálnímu stavu snížena. Tento nežádoucí stav může být mimo jiné způsobený následujícími případy - špatné nastavení modelu, například příliš velký (hluboký, rozvětvený) rozhodovací strom, příliš komplexní neuronová síť, příliš malý vzorek učících dat, nebo chyby ve vstupních proměnných, které nebyly řádně očištěny. Přeučení znamená, že model z dostupných dat předpokládá příliš mnoho,
-
Underfitting (nedoučení modelu)
znamená, že učení modelu bylo chybou nastavení modelu, nebo nedostatkem dat zastaveno příliš brzy a nebyly odhaleny všechny důležité vztahy. Model je příliš obecný a jednoduchý. Například nedoučený strom se skládá z příliš malého počtu pravidel a má málo listů,
-
Pruning (prořezávání)
je jedna z metod optimalizace modelů. Účelem je snížení komplexity modelu. Například u rozhodovacích stromů představuje pruning „prořezávání“ větví modelu, za účelem snížení počtu větví a listů a tím snížení rizika overfittingu, u neuronových sítí zase snížení počtu neuronů a vrstev Hidden Layer,
-
Vyhodnocení prediktivního modelu
- po vytvoření prvních modelů se výsledky těch nejúspěšnějších testují v praxi na nových datech. Na základě predikce se uskuteční rozhodnutí a nastane nějaká akce. Poté se vyhodnocuje, jak moc predikce odpovídá realitě,
vyhodnocuje se úspěšnost modelu v praxi
. Ta bývá zpravidla řádově nižší, než model vykazuje na učících, či testovacích datech. V některých případech může být objektivní vyhodnocení problematické, protože provedená akce ovlivní chování jedince a není tak možné zjistit jeho chování, když by akce nenastala. Příkladem může být marketingová kampaň telekomunikační společnosti zaměřená na odcházející klienty, kde prediktivní modely vyhodnocují pravděpodobnost odstoupení klienta od smlouvy a jeho přechodu ke konkurenci. Klienti s nejvyšším skóre jsou společností osloveni a je jim nabídnuta nějaká výhoda. V tomto případě se však nedá přesně ověřit, zdali klienti, vyhodnocení jako nejnáchylnější k odstoupení, skutečně odstoupit chtěli, tedy zdali je model vyhodnotil správně jako nejnáchylnější k odstoupení. Dá se pouze měřit, kolik lidí skutečně odstoupilo a kolik ne. Řešení tohoto problému spočívá ve využití kontrolních skupin, kdy se záměrně část klientů s vysokým skóre neosloví a sleduje se u nich jejich chování neovlivněné prediktivním modelem.
-
Aplikace prediktivního modelu
- nasazení prediktivního modelu v praxi a využití jeho výstupů pro učinění rozhodnutí. V této fázi je model funkční a
vyhodnocuje nová data
. Na základě výsledků se provádějí akce a realizují rozhodnutí. Díky vyvinutému, naučenému a funkčnímu modelu se upraví procesy, zlepší rozhodnutí a model se dále validuje a vyhodnocuje se jeho úspěšnost na reálných datech.
 6. Poznámka
- Obsah úlohy je v přiloženém PDF dokumentu (zobrazení / stažení - ikonky v záhlaví stránky).
|
|
|
|