|
Úloha
: Návrh transformací dat v BI
|
|
|
|
|
Kód úlohy
Standardní kód úlohy v MBI.
:
|
Autor návrhu úlohy
Jméno a příjmení autora úlohy
:
|
Datum poslední úpravy
Datum poslední úpravy úlohy ve tvaru rrrr.mm.dd.
:
|
Předpokládaná pravděpodobnost užití v praxi
Předpokládaná pravděpodobnost užití úlohy v praxi, hodnoty 0 - 1. Např. 0,7 - úlohu lze využít v 7 z 10 podniků. Hodnoty jsou průběžně testovány a upřesňovány na základě anket a průzkumů.
:
|
|
|
Charakteristiky úlohy
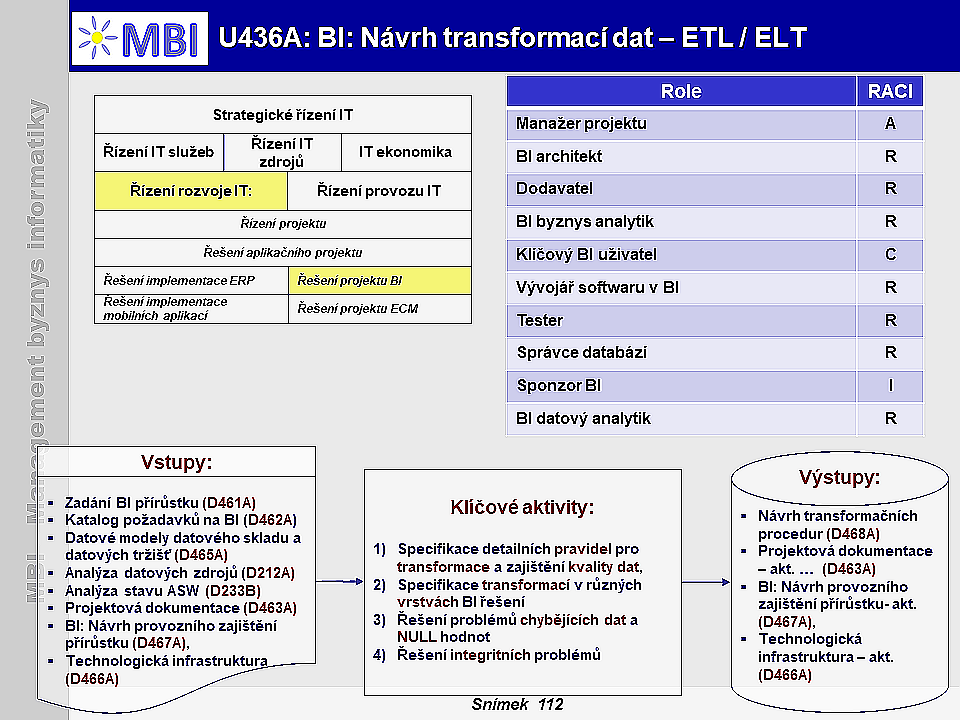
 1. Účel návrhu transformací dat
- Cílem návrhu transformací dat je detailně
definovat transformační pravidla mezi produkčními daty a analytickými daty
uloženými v BI databázích, zajistit odpovídající kvalitu dat a navrhnout komplex čistících a transformačních procedur.
 2. Obsah úlohy transformací dat
- Návrh transformací dat
lze realizovat těmito základními způsoby
:
- využití funkcionality zdrojových systémů,
- využití funkcionality zdrojových databází,
- export dat,
- specializovaný CDC nástroj.
 2.1. Využití funkcionality zdrojových systémů
- Tento způsob získání zdrojových dat
není příliš obvyklý
. Jedná se o případy, kdy se samotná aplikace zdrojového systému stará i o zachycení změn a jejich předání do cílového systému nebo uložiště.
Reálná implementace
často vypadá tak, že daná vrstva aplikace, která zajišťuje komunikaci s persistentní databázovou vrstvou,
uloží změny jednak v primárním a rychlém databázovém systému
aplikace a také asynchronně zašle změny
i do další komponenty
, která zajistí například dávkové nahrání změn do cílového systému nebo uložiště.
- Tento přístup má
několik výhod
. Je zachováno transakční rychlé zpracování typické pro zdrojové systémy, protože aplikace nečeká na potvrzení asynchronního uložení změn. V případě kvalitní implementace nedochází k výraznému zatížení zdrojového sytému a k větším odezvám aplikace. Tím, že se o tuto komunikaci stará speciální vrstva aplikace, tak ve většině případů nedochází k větší pracnosti případného dalšího vývoje nebo úprav aplikace, protože vývojáři jsou od tohoto řešení odstíněni.
- Tento přístup má také své
nevýhody
. Již při nákupu nebo vývoji nové aplikace se musí počítat s požadavkem na tuto funkcionalitu. V případě selhání asynchronního zaslání a uložení změn musí existovat způsob odchycení těchto chyb a také postup, jak danou situaci řešit.
-
Největší nevýhodou
tohoto řešení je, že
nezachytí změny provedené přímo v databázi
. Může se jednat například o zásah databázového administrátora v případě nestandardních situací. Další výraznou nevýhodou je, že v případě použití tohoto způsobu získávání změn do datového skladu je potřeba řešit získání dat z více zdrojových systémů. To vede k tomu, že tento způsob řešení buď musí umožňovat všechny zdrojové aplikace, což je velmi nepravděpodobné vzhledem k tomu, že zdrojové aplikace jsou často starší než datový sklad, nebo to vede k použití různých způsobů získání dat u různých zdrojových systémů, což značně zesložiťuje architekturu řešení a tím i jeho správu a provoz.
2.2. Využití funkcionality zdrojových databází
- Princip tohoto řešení je velmi podobný předchozímu, nenachází se ale na úrovni aplikace, ale je vytvořeno přímo
v databázi zdrojového systému
. Často se jedná o různé
Triggery
, resp. zdrojové kódy spustitelné v databázi, které se aktivují při zvolených databázových operacích. V případě zachytávání změn v datech to jsou především o operace typu Insert, Update a Delete.
- Tento zdrojový kód se poté postará o
zaznamenání změny a provede export této změny do jiné tabulky
nebo souboru. Tato tabulka nebo soubor se v praxi často nazývá jako
rozdílová tabulka
/soubor nebo delta tabulka/soubor. Jako v předchozím případě tyto tabulky nebo soubory obsahují pouze změny provedené ve zdrojových systémech a nikoli celou aktuální množinu dat.
-
Výhodou
tohoto řešení oproti předchozímu je především to, že je schopné zachytit i změny provedené přímo v databázi (například i změnu provedenou databázovým administrátorem přímo nad databází při nestandardních situacích).
-
Nevýhodou
může být potencionální větší zátěž zdrojové databáze, zvláště v případě použití Triggeru, který zapisuje do delta tabulky. V tomto případě může být zátěž této databáze až dvojnásobná, protože každá změna musí být promítnuta dvakrát, jednou do původní tabulky a jednou do delta tabulky. Při tomto řešení také zůstává nevýhoda, že u každého zdrojového sytému je potřeba zajistit získání dat jednotlivě. V případě, kdy zdrojové systémy používají různé databáze, znamená to vývoj, otestování a nasazení kódů a celého řešení na každou takovou databázi zvlášť. To může výrazně prodražit celé řešení a značně zkomplikovat jeho udržitelnost v dlouhodobém horizontu.
2.3. Export dat
- Na první pohled nejjednodušší možností jak získat data ze zdrojových systémů je jejich export z databáze. Tento export může být proveden
pomocí databázového nástroje
, který je součástí dané databáze nebo je dodáván spolu s databází. Může být také proveden
ETL nástrojem
. V obou případech je velmi komplikované exportovat pouze data, která se změnila od posledního exportu. Důvodem je, že rozpoznání těchto dat je problémové. Z tohoto důvodu jsou někdy v zdrojové databázi použity sloupce, které identifikují záznamy, které se od posledního exportu změnily. Často tyto sloupce nesou názvy jako „datum_modifikace“, „audit_sloupec“, „timestamp“ a podobně.
-
Problém
tohoto řešení je v jeho složitosti. Při každé změně v datech se musí hodnota tohoto sloupce také vhodně změnit. Každá zdrojová aplikace, která s těmito daty pracuje, musí s touto povinností počítat. To samé platí i pro ruční zásahy do dat v případě nestandardních situací.
- Vzhledem k tomu, že tento princip je potřeba zajistit ve všech zdrojových databázích a ve všech jejich strukturách, stává se celé řešení velice
náročné na provoz a případné rozšiřování
. Otázkou je také důvěra v takováto řešení, zejména to, že všechny operace se zdrojovými daty správně modifikují určený sloupec. Například malá chyba v drobném rozšíření zdrojového systému může způsobit, že změny z určité části zdrojového systému nebudou zachyceny. Cílový systém, jakým je například právě datový sklad, ale obvykle nemá prostředky jak tuto chybu rychle odhalit. S odstupem času se také odhalení takovýchto chyb stává velmi složitým.
- Výše uvedené důvody většinou vyústí ke zvolení daleko jednoduššího řešení, jakým je celkový export dat. Při celkovém exportu dat dochází k získání všech relevantních dat ze zdrojových systémů a jejich nahrání do cílového systému. Je pak na cílovém systému aby rozlišil nová data, změněná data a smazaná data a vhodně je zpracoval.
-
Výhodou
tohoto řešení je poměrně jednoduché provedení, které lze uskutečnit bez změn v logice zdrojových systémů. Toto řešení je také poměrně robustní ve smyslu odolnosti k chybám. Tím, že dochází k celkovému exportu dat, je velmi nízké riziko nepodchycení veškerých změn vzniklých ve zdrojových systémech.
-
Nevýhodou
tohoto řešení je značné vytížení zdrojových systémů v době exportu dat. Proto se v případě použití tohoto řešení často provádí tento export v době, kdy jsou zdrojové systémy méně vytěžované, obvykle během nočních hodin. To má za důsledek, že aktuálnost dat v cílovém systému je dána tím, kdy jsou zdrojové systémy k dispozici pro tento celkový export.
- V případě exportu během nočních hodin jsou data cílovému systému dodána se zpožděním jednoho dne. U nadnárodních společností, které operují přes více časových pásem, může vzniknout stav, kdy nelze nalézt žádné časové okno vhodné pro export dat.
- Pokud se zvolí
cesta celkového exportu dat
a najde se pro něj vhodné časové okno, je stále toto
řešení značně neefektivní
. Je totiž velice nepravděpodobné, že by zdrojové systémy měnily mezi jednotlivými exporty veškerá svá data. Je možné, že s veškerými daty pracují, například je používají pro čtení a vhodné zobrazení uživateli, obvykle ale mění jen malou část svých dat.
- V reálném prostředí
lze poměrně dobře odhadnout
(například podle dvou po sobě jdoucích exportech) procentuální změnu ve zdrojových datech. V případě, kdy by se zjistilo, že se ve zdrojovém systému mění pouze 5 % všech dat mezi jednotlivými celkovými exporty a datová základna tohoto zdrojového systému by byla 200 GB, dochází ke zbytečnému přenosu 190 GB dat.
-
Nejedná se tu jen o samotnou náročnost přenosu dat, ale o celý proces s tím související
. Dochází totiž ke zbytečnému vytížení zdrojového systému, který musí těchto 190 GB poskytnout, poté následuje přenos těchto dat po infrastruktuře a následně k samotnému nahrání dat do cílového systému. Cílový systém je poté ještě vytížen tím, že musí data vhodně zpracovat, tedy ve většině případů, je na něj přesunuta poměrně výpočetně náročná úloha, a to zjistit, která data z oněch celkových 200 GB byla změněna a jsou nezbytná k dalšímu zpracování.
- Čím je potřeba mít data aktuálnější v cílovém systému, tím častěji při použití tohoto řešení dochází ke zbytečnému vytěžování všech tří prvků, tedy zdrojového systému, infrastruktury a cílového systému. Z tohoto důvodu se nejeví toto řešení jako vhodné k běžnému použití, zvláště pak v prostředích, kde zdrojové systémy mají velké datové základny.
2.4. Specializovaný CDC nástroj
- Principem fungování specializovaného CDC nástroje je
schopnost načítat provedené změny v databázích z jejich databázových logů.
Ve většině případů tedy není potřeba nahrávat data z těchto databází a z jejich diskových úložišť, ale pomocí znalosti databázových logů lze odvodit, jaká data byla jak změněna a na základě toho vyvodit potřebný stav v cílovém uložišti.
- Tímto způsobem se
lze vyhnout výraznému zatížení zdrojových systémů a zároveň je možné potřebná data zpřístupnit pro další zpracování.
Za další výhodu může být považováno relativně rychlé zachycení změn ve zdrojových systémech, a tedy tyto změny mohou být velmi rychle zapisovány do cílového systému a zpřístupněny tak k dalšímu zpracování.
- Tento způsob získání datových změn ze zdrojových systémů na první pohled nepřináší výrazné nevýhody, tak jako předchozí uvedené možnosti. V případě nasazení specializovaného CDC nástroje v konkrétním prostředí lze spatřit velkou
výhodu
zejména v případě, kdy zvolený nástroj umí změny získávat ze všech zdrojových systémů, které jsou provozované v daném prostředí. V tomto případě by nasazení tohoto specializovaného nástroje mohlo vést ke zjednodušení používaného řešení, kdy místo různých způsobů získávání dat ze zdrojových systémů by existoval jednotný způsob získávání zdrojových dat. Správa takového řešení a jeho provoz by tak mohl být efektivnější.
 3. Podmínky úspěšnosti úlohy
- Předpokladem je dostupná a kvalitní dokumentace zdrojových databází,
- Kvalitní systém, resp. pravidla pro zajištění kvality, čištění dat, a jejich konsolidaci,
- Využití vhodných SW prostředků pro transformace, buď integrovaných do databázových systémů pro BI, nebo specializovaných pro ETL,
- Integrace nástrojů pro čistění a konsolidace dat do vybraného software.
4. Klíčové aktivity návrhu transformací dat
-
Specifikace detailních pravidel pro transformace a zajištění kvality dat
- je detailní analýza existujících datových zdrojů a definování pravidel pro dosažení požadované kvality dat. Zahrnuje i stanovení parametrů pro kontroly a transformace dat po stránce obsahové (datových struktur), technické i organizační (stanovení periodicity aktualizace modelů, zodpovědnosti za vstupní data). Klíčovou náplní je tu však skutečné zajištění kvality dat návrhem systému kontrol a opravných operací, neboť čistota dat je jedním z kritických faktorů úspěšnosti jakékoli BI aplikace.
-
Specifikace transformací v různých vrstvách BI řešení
- Na základě pravidel definovaných koncovými uživateli (business pravidel) a navržené technologické architektury se určují požadované transformace mezi jednotlivými komponentami, resp. vrstvami BI řešení, případně se upravují stávající ETL procedury podle nároků na transformace řešeného přírůstku. Definuje se zde obsah a organizační stránky transformace mezi produkčními databázemi, DSA, operativním datovým skladem, datovým skladem a datovými tržišti.
-
Řešení problémů chybějících dat a NULL hodnot
- Neúplné datové struktury a častý výskyt NULL hodnot je zcela běžným problémem produkčních databází. Důvodů pro to je několik, od špatné disciplíny uživatelů transakčních aplikací, přes neúmyslné omyly a chyby až po objektivní neznalost nebo nemožnost získání některých informací (např. identifikační nebo kontaktní údaje zákazníka apod.). Zatímco transakční aplikace se s tímto problémem obvykle vyrovnají tím, že chybějící data prostě nezobrazí, u analytických aplikací je to podstatně složitější v tom, že chybějícími daty může být narušena vypovídací schopnost a kvalita výsledných analýz a reportů.
-
Řešení integritních problémů
- je obdobné jako u běžných databázových aplikací a spočívá v porušení nebo neexistenci předpokládaných nebo definovaných vazeb mezi záznamy jednotlivých databázových tabulek.
|
|
|
|