|
Metoda
: Metodika CRISP–DM
|
|
|
|
|
Kód metody
Standarní kód metody v MBI
:
|
|
|
Popis, obsahové vymezení
Obsahové vymezení metody - rekapitulace základních principů ve vztahu k řízení informatiky
 1. Metodika CRISP–DM
-
Cross-Industry Standard Process for Data mining (CRISP-DM)
je metodika pokrývající
kompletní proces data miningových úloh
(Rauch, Šimůnek 2014, str. 19).
- Metodika, která je při použití
nezávislá na konkrétním odvětví
společnosti zkoumající data,
na použitých softwarových nástrojích
a také na aplikaci konkrétní metody či algoritmu v oblasti data miningu. (Chapman et al. 1999, 2000, str. 1)
-
Chapmanovo CRISP-DM
představuje standardizovanou a volně dostupnou formu vhodného přístupu k řešení data miningových problémů definovaných v rámci obchodních či výzkumných oddělení společnosti.
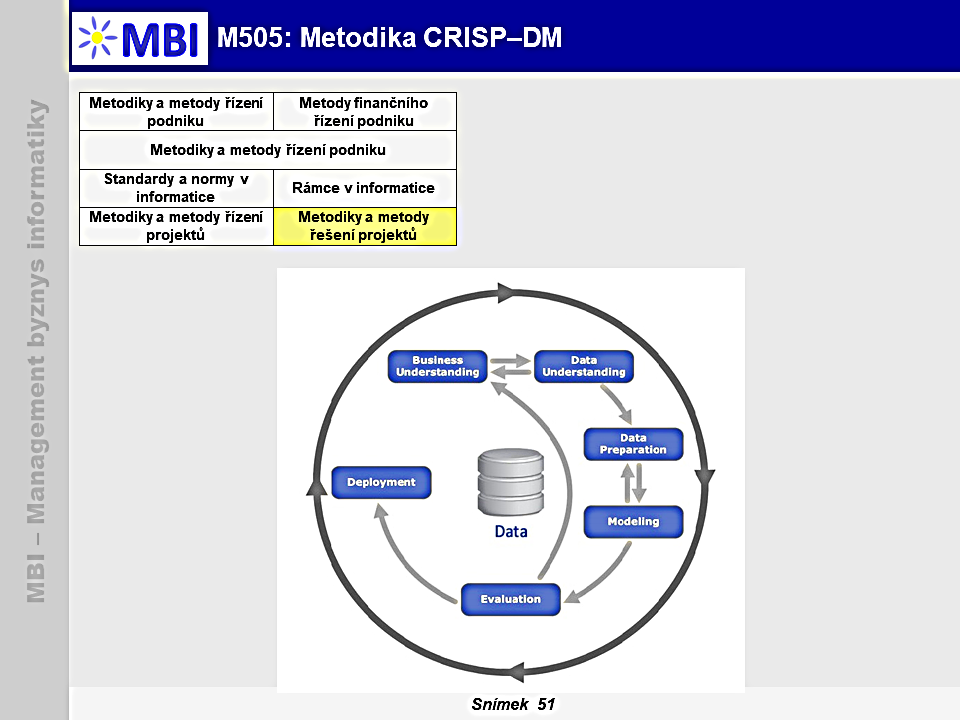
- Dle CRISP-DM sestává
každý data miningový projekt z šesti vzájemně navazujících fází
. Posloupnost těchto fází je adaptivní, což znamená, že následující fáze je obvykle velmi silně ovlivněna výstupy vytvořenými v rámci fáze předchozí.
- CRISP-DM je
znázorněna šipkami (viz základní slide)
se zpětnou orientací, kdy je možné se po zpracování jedné fáze vrátit k fázi předchozí a provést potřebné, z následné fáze plynoucí, změny.
- Vnější kruh v rámci diagramu symbolizuje
cyklický charakter celého procesu
, u kterého není neobvyklé, že po vyhodnocení výstupů úlohy (stejně tak i po využití získaných znalostí) je vhodné se vrátit na začátek celého procesu a překonfigurovat vstupní předpoklady tak, aby došlo k co možná největšímu zlepšení celého procesu a jeho výstupů. Jednotlivé fáze procesu dobývání znalostí z databází dle metodiky CRISP-DM jsou v dalším přehledu.
1.1. Porozumění problematice/zkoumané oblasti
- V rámci této fáze je kladen důraz na
porozumění požadavkům a cílům projektu z manažerského pohledu
, dále probíhá hodnocení rizik a přínosů, kalkulace potřebných zdrojů a nákladů.
- Je také stanoven předběžný plán průběhu prací. Je také nutné porozumět zkoumané oblasti, ze které pocházejí zkoumaná data, v rámci které je jejich analýza prováděna.
- Data miningové úlohy je možné provádět
v rámci různých doménových oblastí,
které se mohou v mnohém lišit, jako jsou telekomunikace, marketing, strojírenství, doprava atd.,
- Je třeba
disponovat znalostí specifik zkoumaného odvětví
k rozlišení mezi novými zajímavými a již známými znalostmi plynoucími z datové analýzy.
1.2. Porozumění datům
- Autoři metodiky uvádějí v její dokumentaci
několik kroků, které je nutné s daty v rámci této fáze provést
: (Chapman et al. 1999, 2000, str. 18):
-
Sběr vstupních dat
– v tomto kroku je nutné získat data nebo alespoň přístup k nim ze zdrojů definovaných v rámci projektu. Výstupem tohoto kroku je seznam získaných datových sad a metod, pomocí kterých je možné data získat, a seznam problémů, které se v průběhu sběru dat vyskytly.
-
Popis dat
– popisem získaných dat je myšleno prozkoumání jejich hrubých a povrchových vlastností jako jsou datové typy, počty záznamů jednotlivých datových sad, významy jednotlivých polích apod. Důležitou částí tohoto kroku je zhodnocení možnosti využití získaných dat v souladu s relevantními požadavky projektu.
-
Zkoumání dat
– ke zkoumání dat jsou nejčastěji využívány deskriptivní a vizualizační techniky, v rámci kterých jsou data zobrazována a zkoumána. Zkoumána je například frekvence výskytu hodnot v rámci jednotlivých atributů, průměry, mediány, maximální a minimální hodnoty atd.
-
Ověření kvality dat
– tento krok je zaměřený na zjištění kvality získaných dat. Jeho cílem je odpovědět na otázky typu: Pokrývají data kompletně zkoumanou oblast v potřebné míře? Jsou data správná, nebo obsahují chyby? V jakém jsou chyby zastoupení? Obsahují data chybějící hodnoty? V jaké míře a kde se vyskytují, jak jsou reprezentovány chybějící hodnoty? Jestliže se v tomto kroku projeví datové chyby, je doporučeno vytvořit seznam jejich možných řešení. Tato řešení jsou silně závislá na zkoumaných datech a obchodních znalostí.
- Příprava dat – Berka popisuje tuto fázi následujícím způsobem: „Příprava dat zahrnuje selekci dat, čištění dat, transformaci dat, vytváření dat, integrování dat a formátování dat.“ (Berka 2003, str. 26). V této fázi probíhá
výběr konkrétních atributů,
ale i jednotlivých záznamů použitých v analytické úloze. Mezi kritéria výběru těchto dat patří relevance ve vztahu k cílům data miningové úlohy, kvalita a možná technická omezení využitých nástrojů jako je množství a datové typy vybraných dat. V rámci
čištění dat
je snaha o získání takové kvality dat, která je vyžadována vybranou analytickou metodou. Může se jednat o vložení vhodných výchozích hodnot nebo nahrazení chybějících hodnot adekvátní metodou apod. Vytváření dat zahrnuje
operaci s daty vytvářející odvozené atributy
, celé nové záznamy nebo transformované hodnoty již existujících atributů. Odvozenými atributy jsou myšleny atributy, které jsou vytvořeny kombinací některých, v datech, již existujících atributů v rámci jednotlivých záznamů. Příkladem může být odvozený atribut ‚marže‘, který odpovídá rozdílu atributů ‚tržby‘ a ‚náklady‘. Pokud jsou různá data týkající se konkrétního objektu uložena ve více tabulkách či datových sadách, jsou
v rámci kroku integrace dat kombinována tak, aby dohromady tvořila nový záznam
složený kombinací relevantních dat týkajících se tohoto objektu. V rámci této integrace může být provedena i agregace dat, pokud není nutné pracovat s detailními záznamy. Příkladem takové integrace může být spojení několika tabulek obsahujících údaje o zákazníkovi, kdy v jedné tabulce jsou osobní údaje zákazníka a ve druhé údaje demografické. Spojením těchto tabulek vznikne nová tabulka obsahující osobní i demografické údaje v rámci jednoho záznamu. Pod agregací dat je možné si představit situaci, kdy není třeba zkoumat jednotlivé nákupy konkrétního zákazníka, ale zkoumaným atributem může být například počet provedených nákupů zákazníka v určitém období.
Formátováním dat jsou myšleny operace s daty, které data upraví v syntaktickém smyslu
. Tyto úkony jsou prováděny v rámci požadavků využitých
nástrojů k následnému modelování dat
. Požadavkem takového nástroje může být například pozice zkoumaného atributu v rámci datové sady, kdy může být vyžadováno umístění tohoto atributu na poslední pozici v datové sadě, nebo nutnost označení každého záznamu unikátním identifikátorem apod. Data mohou být také transformována k účelu splnění specifických požadavků jednotlivých algoritmů data miningu. Může se jednat například o diskretizaci (rozdělení numerických dat do intervalů) či binarizaci (převedení kategorických dat na data numerická).
Výstupem této fáze
je upravená
datová sada vyhovující požadavkům konkrétního data miningového řešení
a využitým algoritmům zpracovávajícím data.
1.3. Modelování
-
Larose popisuje tuto fázi pomocí čtyř stručných bodů,
které jsou: (Larose c2005, str. 7):
-
Výběr
a aplikace vhodných modelovacích technik.
-
Kalibrace parametrů
vybraného modelu (data mining algoritmu) za účelem jeho optimálního nastavení a získání relevantních výsledků.
- Mít na paměti, že často k řešení jednoho data miningového problému je
možné využít několik rozdílných technik
a modelů. Obecně se doporučuje využít více různých technik a jejich výsledky kombinovat.
- Z předchozích kroků je možné, že vyplyne potřeba
vrátit se zpět k fázi přípravy dat
a jejich modifikaci tak, aby bylo pracováno s co nejvhodnějšími daty přizpůsobenými konkrétní zvolené data miningové technice.
1.4. Vyhodnocení výsledků
- V této fázi dochází k
vyhodnocení získaných znalostí,
které jsou relevantní z pohledu data miningových metod. Tyto znalosti je však nutné
vyhodnotit z pohledu manažerů
, pro které jsou získané znalosti určeny a kteří určí, zda došlo k naplnění cílů úlohy definovaných v jejím zadání.
- V rámci evaluace výsledků klasifikační úlohy je
možné zjistit například následující:
„Výsledky testování klasifikačních znalostí ukázaly, že systém byl příliš přísný, tedy rozpoznával klienty rizikové, ale v určitých případech (obzvláště u vyšších půjček) za rizikové označil i klienty bonitní. Bylo tedy rozhodnuto, že ve všech pobočkách banky bude využíván program, který bude rozhodovat o úvěrech do určité částky.“(Berka 2003, str. 27).
- Nakonec dochází k
určujícímu rozhodnutí
o způsobu využití získaných výsledků.
1.5. Využití výsledků
- V poslední fázi dochází k
sumarizaci využitelných výsledků úlohy
a k definici způsobu využití výsledků jednotlivými koncovými uživateli.
- Výstupy data miningové úlohy mohou být
ve formě závěrečné zprávy o dosažených výsledcích nebo ve formě softwarového řešení
automatizujícího proces celé data miningové úlohy v uživatelsky využitelné podobě.
- Nejdůležitější fáze je
porozumění problému, která zabere 20 % času, ale má 80% význam
. Časově nejnáročnější je fáze přípravy dat, která zabírá 80 % času s 20% významem, přičemž modelování a analýza zkoumaných dat zabere 5 % času a má 5% význam. (Berka 2003, str. 28).
 2. Poznámky, reference
- BERKA, Petr. Dobývání znalostí z databází. Praha: Academia, 2003. ISBN 80-200-1062-9.,
- RAUCH, Jan a Milan ŠIMŮNEK. Dobývání znalostí z databází, LISp-Miner a GUHA. Praha: Oeconomica, nakladatelství VŠE, 2014. Odborná kniha s vědeckou redakcí. ISBN 9788024520339.,
- SKALSKÁ, Hana. Data mining a klasifikační modely. Hradec Králové: Gaudeamus, 2010. Recenzované monografie. ISBN 9788074350887.
- CHAPMAN, Pete, et al. CRISP-DM 1.0: Step-by-step data mining guide. In: The Modeling Agency [online]. Pittsburgh: One Oxford Centre, Copyright © 1999, 2000 [cit. 2017-11-21]. Dostupné z: https://www.the-modeling-agency.com/crisp-dm.pdf,
- LAROSE, Daniel T. Discovering knowledge in data: an introduction to data mining. Hoboken, N.J.: Wiley-Interscience, c2005. ISBN 9780471666578.
|
|
|
|